

Machine learning algorithms are often mistaken as objective analytics and decision-making solutions to human inefficiencies.
Paradoxically, humans often make machine learning algorithms inefficient by way of biases. These biases include sample bias, reporting bias, prejudice bias, confirmation bias, group attribution bias, algorithm bias, measurement bias, recall bias, exclusion bias, and automation bias.
Machine learning is highly susceptible to many forms of bias that can undermine model performance. After all, AI is assembled by humans, and humans are innately biased, so It stands to reason that some of that bias will inevitably slither its way into a machine learning model or two.
It is important to consider both an AI model’s algorithm as well as the data it’s trained on. While in some cases there might exist flaws in the algorithm, oftentimes there are many potential issues that can exist in the training data itself or the way that training data is labeled.
Knowing what to look for is the fastest way to identify these flaws. That is why it is important to understand the different types of bias that can exist when using machine learning for problem-solving. With that in mind, here are 10 ways that bias can sneak its way into a machine learning model.
You can also read other articles that I have written on the topic of Machine Learning, including in-depth tutorials here.
Table of Contents
- Sample Bias
- Reporting Bias
- Prejudice Bias
- Confirmation Bias
- Group Attribution Bias
- Algorithm Bias
- Measurement Bias
- Recall Bias
- Exclusion Bias
- Automation Bias
- Conclusion
Sample Bias
Sample bias, or selection bias, is one of the most common ways bias can influence a machine learning model. This happens when the sample data selected to train the model doesn’t accurately reflect the real-world data (population data) that it will ultimately assess.
One key mistake that leads to sample bias is a lack of randomization during the sample selection process. Ideally, a sample should capture data that equally represents all facets of the real-world data that the model is trained for.
Example
Consider an AI trained to respond to a users’ voice inputs in English.
The data scientist may only select Americans as sample speakers from which the model will learn, even though the model is expected to be used globally. This sampling bias will negatively impact the model’s performance when it is tasked with recognizing English spoken with different accents, such as in the UK, Australia, or elsewhere.
Correction
Sampling bias can be avoided by thoroughly examining the environment to which your model will be exposed. Diversity in datasets with well-rounded characteristics is paramount when preparing a model to accurately recognize or respond to the wide array of inputs the model will receive.
Reporting Bias
Reporting bias relates somewhat closely to sample bias in that it has to do with the training dataset not accurately representing data in the real world (population data). This issue is often caused by the frequency of some data points being more observable than others, hence the name, reporting bias; because some types of data may be reported on disproportionately to others.
One way reporting bias can arise is if data collecting methods work really well for one type of data, but overlook or miss other types of data. Thus, the reporting of some data is more frequent than that of others, especially when data is aggregated from disparate sources.
Example
Perhaps a model is factoring in survey inputs from customers. The survey was sent to all individuals who bought a particular product, but 80% of them did not have strong enough views to take a survey.
Meanwhile, the remaining 20% did have strong enough views, so they did take the survey. This disproportionate response rate could trick the model in its perception of the opinion of the average buyer, thus causing a biased output.
Correction
Ensure that your data sampling methods are thorough so that they capture edge cases where important data might exist.
It is important to understand how the particular data of interest are organized in their natural form, so as a data scientist, you know how to collect and record it appropriately. It is also helpful to understand best survey practices and fundamental survey methodology to avoid situations as described in the example above.
Prejudice Bias
Another common type of bias is known as prejudice bias. As the name implies, this is the assumption of certain attributes based on immutable characteristics, such as race, nationality, gender, etc. This particular type of bias is more difficult to guard against because it is not always obvious where it could exist.
Statistically speaking, a particular gender might be overrepresented in a specific area or field in real life. Your data sample could be very accurate in that it represents its real-world counterpart down to a tee.
However, the issue arises when the machine learning model misinterprets these kinds of trends as a causal relationship between variables, for example, gender and a job title.
Example
Imagine a model analyzing differences between men and women. One correlation it might develop is regarding parental roles between the two genders. It can become easily apparent that fathers must be men, and mothers must be women, and it would be correct in concluding that.
However, this type of correlation could backfire when examining something like the presidents of the United States. Given that the U.S. has never had a female president (as of 2021), the model could also assume that U.S. presidents must be men, whereas this is actually not true.
In fact, women have run for president in the past, but the model might not have had a way of knowing that.
Father → Man (correct assumption)U.S. President ⥇ Man (incorrect assumption)
Correction
Diverse sample datasets will typically remove a lot of potential prejudice bias. As we saw in the example above, there are still ways it can sneak into a model. A data scientist could examine where prejudice could occur, then include examples in the dataset that prove the exceptions exist.
It is also possible to do post-processing on the model’s output to remove instances of prejudice bias.
Confirmation Bias
Whereas the previously discusses biases result from skewed dataset samples, confirmation bias lies within the human’s interpretation of the machine learning model’s results.
The nature of this bias is formed when a researcher either consciously or subconsciously molds data to fit a hypothesis or preconceived notion rather than objectively listening to what the data is saying.
Data scientists may select for specific results while dismissing others until the model behaves in line with their expectations, which ultimately results in confirmation bias.
Example
This can be as simple as examining trends in something like medicine sales. A researcher who believes that people are healthier today than they were in recent years may look at a downward trend in medicine sales and believe it supports his hypothesis.
However, this downward trend could be primarily caused by another factor such as spikes in medicine prices.
Correction
Whether in machine learning or any other research discipline, it is crucial to challenge the validity of an idea or hypothesis. When examining data, understand what other conclusions could be drawn from it.
Confirmation bias is often the result of overlooking some key element in the data or in the environment from which the data comes.
Group Attribution Bias
Group attribution bias is similar to prejudice bias in that it draws a causal relationship between attributes and outcomes. However, this type of bias refers more specifically to lumping data points into the same groups based on observed correlations.
Models with group attribution bias will assume that what is true for some members of a group must be true for all members of that group.
There are 2 types of group attribution bias:
In-group: forming assumptions among members within a group.Out-group: forming assumptions among members outside of a group
Example
Suppose there is an AI that ranks resumes against job descriptions. The AI could begin to group together resumes with higher education as great fits, since candidates with master’s degrees and PhDs might typically have more potential than candidates without them.
However, this could potentially overlook other candidates who lack higher education but still have many redeeming qualities like relevant work experience and unique skillsets.
Correction
Group attribution bias often slips through the cracks since the similarities and differences between data points can be very discreet and hard to detect by human eyes.
One way to safeguard against this is to train models with flexibility by providing diversity in dataset samples that teach the model to avoid grouping elements together based on surface-level similarities.
Algorithm Bias
Algorithms in practice will always contain some bias. One way to think of bias is the degree to which a model will make predictions based on the given data. On the other hand, there is variance, which is the degree to which a model will factor in different data points before giving an output.
Too much bias will obviously result in a high error output, as it suggests that the model is not considering either the correct kinds of data, the correct amounts of data, or both. At the same time, however, too high of variance will cause a model to depend too much on the sample dataset given, causing it to lack foresight and an inability to predict trends in other real-world data sets.
Therefore, it is important for an algorithm to find the optimal balance between bias and variance. In summary, an algorithm’s bias can manifest itself in 2 kinds of ways in machine learning models:
Under-fitting (high bias): Occurs when a machine learning model does not present a meaningful relationship between data inputs and predicted output; high error output. Over-fitting (high variance): Occurs when a machine learning model is shaped too closely around its sample dataset as it accommodates too much noise; does not fit other datasets.
Example
Imagine predictive analytics in e-commerce.
Predicting buyer behavior based only on one attribute, like age, will inevitably result in very high bias and a rigid algorithm. Conversely, accounting for each buyer’s entire life history will result in too much noise that undermines any meaningful structure to the AI model.
Algorithms must find a balance between rigidity and fluidity.
See the diagram below that illustrates this idea with white and black plotted points. A high biased structure under-fits the dataset because it does not accurately differentiate between the positions of the opposing colored dots, as illustrated by the red line.
In contrast, a high variance model over-fits its dataset because it pays too close attention to the exact position of each and every data point.
The graph on the far right shows a much better generalization between the different points. While there is some error, the likeness that the model will fit many other datasets is much higher.
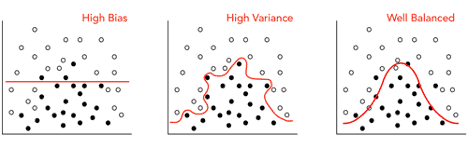
Correction
To avoid algorithm bias, it is up to the data scientist to determine the best balance between rigidity and fluidity. Testing a model’s performance with many different sample datasets will be a good indicator of how much algorithm bias is influencing the model.
Measurement Bias
Including the correct kinds of data in a sample dataset is important, but how that data is collected may be even more important.
Measurement bias occurs when there is a flaw in collecting or measuring data for a sample dataset. This is particularly common in methods like polls or surveys.
Measurement bias could also root in untested measurement methods or the use of only 1 type of measurement method. Untested measurement methods could obviously produce a yield that is different from what’s expected. The use of only 1 measurement method will consequently train the model to optimize itself specifically around that specific source of data.
Example
Imagine once again an AI trained to recognize and respond to voice inputs. If the majority of input samples are recorded only on 1 type of microphone, the model is only trained to recognize input quality from that particular type of microphone.
This can become very problematic once the AI is released in software that’s accessed by thousands of users with different devices with varying qualities of microphones. Therefore, it is crucial to include different measurement methods that are tested to provide very accurate results.
Correction
When measuring data, simply utilize several well-tested methods and analyze each of their outputs before passing them onto the machine learning model.
For surveys, it is important to ensure that the best surveying practices are conducted to mitigate skewed results.
Recall Bias
Bias can also sneak its way into training data during labeling. Any mistakes when labeling data can possibly contribute to confusion and inconsistencies in the model’s output. Errors in data labeling can also be a result of a human’s skewed perception.
When it comes to classifying data, there could easily be instances where different analysts can interpret data differently. In this regard, the model’s outputs are essentially reflections of the humans’ perceptions of the training data they labeled.
Example
Let’s return to the example of the AI ranking resumes. For a model like this to learn on a dataset, it must first see examples of resumes that are explicitly labeled with information pertaining to their unique ranking.
This phase is extremely important because it sets the basis for the model’s logic. If the human analyst mistakenly perceives objectively poorer resumes as more favorable to objectively better resumes, then the model will be negatively impacted by this recall bias.
Correction
Recall bias can be avoided simply by ensuring that trained experts are left responsible for labeling and interpreting data. In the example discussed above, a great way to prevent mislabeling of data is to consult hiring managers or subject-matter experts in relevant fields who rank resumes regularly in their professions.
Exclusion Bias
While mislabeling data can introduce bias, simply removing data can as well.
Removing extraneous data from a dataset can be a good idea as it reduces the noise that could distract the model. Other times, however, this data could provide useful links to the model that would be overseen by human eyes.
Excluding such pieces of data that would otherwise be useful to a machine learning model in making accurate predictions is known as exclusion bias.
Example
Consider a model that focuses on predicting customer behavior of residents within a certain state in the United States. The customers’ addresses are provided in the collected data, but the data scientist decides to omit the city addresses since they all live in relative proximity to each other.
This may seem justified, although it could create a problem if the spending habits or preferences differ between those who live in the rural areas of the state versus those who live in the suburban or urban areas.
Correction
Once again, it is very important to have training datasets processed by expert data scientists. This increases the likelihood that the relevance of each piece of data will be accurately assessed, and only the truly extraneous info will be omitted.
Automation Bias
Lastly, there’s automation bias, which occurs when results generated from automated systems are more trusted than those that come from non-automated systems. This can easily become problematic, especially when any of the previously discussed biases make their way undetected into the model.
Example
In this last example, let’s return to our resume-ranking AI for a final time.
This is where automation bias can have a detrimental effect in the real world. In fact, there have been actually reported instances where real resume-ranking AI systems were found to have prejudice bias and group attribution bias while filtering through applicants’ resumes.
As a result, the companies that developed the AI had to act very quickly in fixing their models to not only mitigate the bias but also ensure that the correct resumes were being considered for the right jobs.
Correction
Once a machine learning model becomes trusted, it is important to continually assess its performance and test it for areas of improvement.
There will always be some degree of bias in a model.
Therefore, too much trust in its accuracy could potentially stagnate its improvement over time, or even result in having a negative effect that is opposite to what it was intended for accomplishing initially.
Conclusion
Furthermore, everything an AI model outputs is a result of human teaching. An AI’s function is rooted in its algorithms, selected training data, and how that training data is labeled.
Since humans are innately biased, AI models will also be biased. While it is possible to mitigate bias to a very low level, algorithms and training data can never be perfect, and therefore some bias will always sneak its way into machine learning models.
As a result, it is best to both be aware of what types of bias can exist and to continually search for bias in a machine learning model. Then optimize the said model for peak performance.